
Le 15 novembre se déroulait la seconde édition de la Grehack, conférence en sécurité prenant place à Grenoble, au cœur des Alpes. Calypt était sur place au milieu de 250 participants pour une douzaine de talks dispensés par des chercheurs du monde entier, ainsi que pour son CTF réunissant 37 teams et environ 140 personnes prêtes à en découdre sur des challenges plus ou moins corsés.
Les conférences ont pris place tout au long de la journée du vendredi, après un accueil matinal appuyé à grands renforts de viennoiseries et de cafés les invités ont été priés de se déplacer dans l’amphithéâtre. Après une minute de silence à la mémoire de Cédric Blancher chercheur en sécurité disparu récemment, JP Aumasson a fait une courte introduction. Introduction durant laquelle il a été mis en avant le nombre de papiers soumis (32) et le nombre d’acceptés (9) pour un taux d’acceptation de 28,1%.
Après cette petite présentation d’accueil, c’est parti pour la keynote, ou pas.
Herbert Bos démarre cette keynote en expliquant que la sienne ne sera pas très conventionnelle, et qu’il va plus faire état des erreurs mémoire passées, présente et futures pour faire un constat : malgré le fait que la plupart de ces erreurs aient plusieurs décennies, elles restent encore à l’heure actuelle un problème majeur. Et pour ce talk, il va se concentrer sur les buffer overflows, très souvent présents dans les top 3 annuels des failles les plus dangereuses, et bien que beaucoup de recherches aient été faites pour s’en protéger (NX bit/DEP, Canaries and cookies, ASLR), ils ont toujours été contournés.
Il a également parlé du dowsing, technique consistant à faire du fuzzing ciblé afin d’identifier des vulnérabilités dans du code. Les méthodes classiques de testing automatique ne scale pas très bien et le nombre d’états augmente de façon exponentielle et le temps de test peut prendre un temps bien trop grand (Aucune vulnérabilité trouvé dans Nginx en 8h).
L’idée serait donc de faire du dowsing, en ciblant des petits et potentiellement suspicieux morceaux de code : on utilise une stratégie basée sur l’analyse du flow d’exécution en classant les portions de codes selon plusieurs critères : instructions, casts, … Avec ça on devrait pouvoir analyser du code dans des temps raisonnable afin de trouver des vulnérabilité avant la release.
Ensuite c’est Juan Caballero qui nous a parlé de Specialization in the malware distribution ecosystem. Talk très intéressant basée sur une réalité : le cybercrime est la pour faire de l’argent, et cet argent est généré par plusieurs méthodes : vols de numéros de cartes bleues, spam, DDoS, Click fraud, minage de bitcoin sur des systèmes compromis, ransomware, VPN.
Les organisations criminelles vont donc chercher à monétiser une machine avec un malware, différents moyens de distributions sont recensés :
- Fake Anti-Virus avec remote connexion ;
- Keygen infecté ;
- Via les SPAM comme vecteur.
Un véritable entrepreneuriat s’est mis en place avec des organisations complexes et bien huilées.
Pay-per-Install :
Des clients paient pour que leur malware soient installés sur un nombre X de cibles. Cela permet de réduire l’investissement, d’avoir plusieurs vecteurs de distributions, de passer par des intermédiaires pour la partie ‘technique’. Cette méthode possède quand même des inconvénients : manque de contrôle, une même machine peut être infectée par plusieurs malwares, une partie du bénéfice est reversé aux intermédiaires techniques.

Drive-by-Download :
Redirections multiples jusqu’à un serveur d’exploit qui essaiera d’utiliser une faille dans le browser de la victime. Le but est de convertir le trafic en installations, le taux de conversion constaté varie entre 6 et 12% ce qui est énorme. Cette méthode est basée sur 3 besoins : un exploit kit, un serveur d’exploit (Harware + hosting) et du trafic. On s’approche ici de l’EaaS (Exploitation-as-a-Service)
Exploitation-as-a-Service :
Le but ici est de louer un serveur d’exploit opérationnel : configurable par le web, avec une localisation choisie (ISP, geographiquement), et avec un exploit kit fourni avec une licence simple ou multi domain (Le prix d’un exploit kit varie, par exemple pour BlackHole : $50/semaine, $500/mois). Il “suffit” ensuite de rediriger les victimes via le trafic sur le serveur.
Après cette présentation des différents moyens de distributions, Juan nous a expliqué comment lui et son équipe avaient procédé afin de les analyser au sein d’une infrastructure complète parmi lesquels :
- une collection de malware obtenus par divers moyens : Warez, live trafic, pièces jointes, manuellement, honeypots… Souvent un même malware est retrouvé depuis différentes sources avec des signatures différentes (packers, chiffrement) ;
- Une exécution ces malwares dans des sandbox afin de collecter les informations (IP, domaine) dans le but de les signaler.
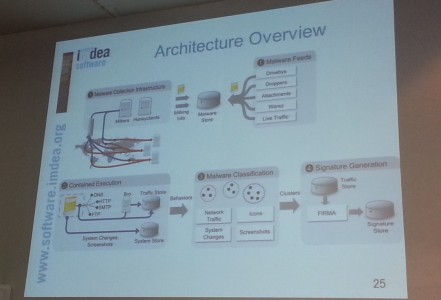
Plusieurs conclusions :
- Le principal vecteur actuel semble être le drive-by download (Ceux qui rapportent le plus d’argent : ransomware, fake AV, clickbots, infostealers) ;
- Beaucoup de repacking des malwares pour échapper aux différentes analyses AV ;
- La durée de vie moyenne d’un serveur d’exploit est de 16h pour l’IP, 2h30 pour le domaine. C’est pourquoi il est important de signaler les deux en même temps ;
- Les malwares sont un business lucratif avec des spécialisations (PPI, Drive-by install) et des moyens d’entreprise derrière cela.
Pour plus d’informations : http://malicia-project.com/
Après cet éclairage sur le fonctionnement des réseaux criminels liés aux malware c’est la première pause de ce Grehack 2013. Tout le monde se dirige dans le hall afin de boire un café, discuter entre confrères, profiter des dernières viennoiseries. 25 minutes plus tard, il faut y aller, un autre talk va commencer.
C’est Thomas Dullien (aka Halvar Flake), le fondateur de Zynamics (binDiff ça vous parle ?) maintenant chez Google, qui a pris la parole pour un exposé invité (le “golf” des conférenciers selon ses dires), intitulé The many flavours of binary analysis. Cette présentation était une vue d’ensemble des différentes techniques d’analyse de binaires et de reverse engineering. Après avoir expliqué qu’il trouvait le reverse awesome parce qu’il réunissait : de l’ingénierie de bas niveau, de l’informatique théorique et de la recherche d’informations ; Halvar Flake nous a rappelé les différentes raisons à l’analyse :
- Analyse de malware ;
- Découverte de vulnérabilité, évaluation de la sécurité ;
- Développement de vulnérabilité.
Il a ensuite énuméré différentes méthodes d’analyse en rappelant les avantages et inconvénients :
- Fuzzing ;
- Dynamic instrumentation ;
- Taint tracking ;
- Patch diffing ;
- Symbol retrieval / porting ;
- Symbolic/concolic exec ;
- Abstract interpretation ;
- UIs for program understanding.

Une remarque faisait état des Service Pack chez Microsoft, en effet les SP corrigeant des failles pour un OS impliquent en général que l’itération précédente de l’OS ne sera pas patché, par exemple, en examinant le SP1 de Win8 est-il possible d’obtenir des 0days pour Win7 ? Probablement selon Halvar, qui en revient à ce qu’il disait au début : le reverse c’est awesome.
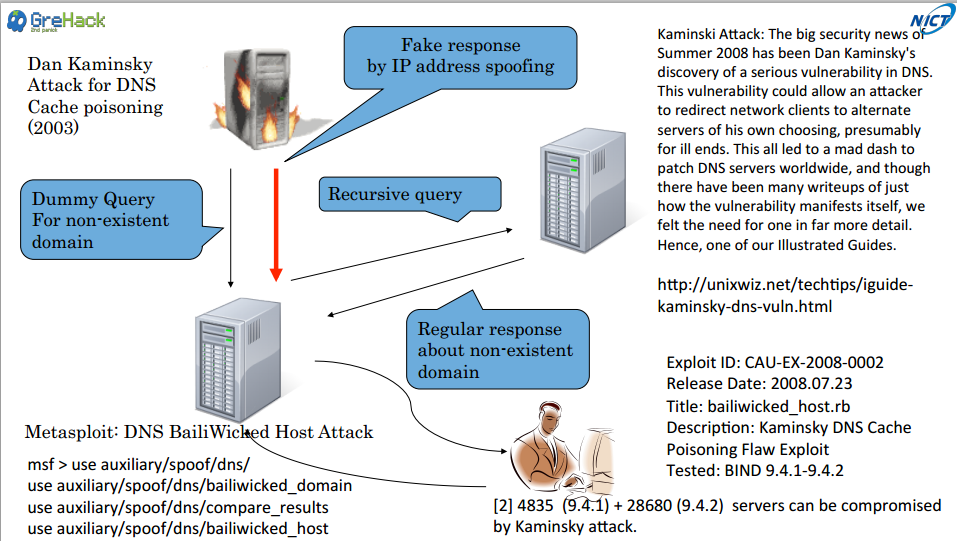
Après ça, c’est Ruo Ando, chercheur en sécurité japonais, qui prend la parole pour présenter les travaux qu’il a mené avec son équipe et intitulés Unraveling large scale geographical distribution of vulnerable DNS servers using asynchronous I/O mechanism.
Ils ont analysés des serveurs DNS déployés sur Internet afin d’en obtenir des renseignements : localisation et version du soft. Ils ont réussi à collecter des informations sur 30,285,322 serveurs en 26 heures en utilisant la librairie LibEvent (qui fournit des mécanismes d’I/O asynchrones) couplé à un cluster de MongoDB. Leur architecture leur permet des scans très rapides.
Le résultat du monitoring est un peu triste :
- Plus de 10,000 serveurs utilisent toujours des versions anciennes et vulnérables de BIND ;
- L’attaque de Kaminsky est possible sur 4,835 serveurs en 9.4.1 et 28,680 en 9.4.2 ;
- 24,971,990 Open Resolver serveur ont le flag RA mis a true (possibilité d’amplification DDoS).
Une jolie méthode d’analyse à grande échelle tout en pointant les problèmes actuels des serveurs DNS.
Eireann Leverett a continué ce Grehack en présentant le travail qu’il a fait avec Reid Wightman en rapport avec SCADA : Vulnerability Inheritance in Programmable Logic Controllers.
200 modèles de PLC issus de différents vendeurs utilisent une même librairie : CodeSys Runtime qui donne un environnement de développement sur ces composants, elle est très utilisée car elle permet aux fabricants de réduire les coûts.
Cette librairie possède plusieurs problèmes de sécurité introduit à la phase de design du protocole d’authentification :
- Une version ne possédait pas d’authentification ;
- 3S Software a fait un patch pour en ajouter une, il faut que les clients mettent à jour le firmware (chose très rare pour des PLCs) ;
- Vu qu’il faut pouvoir lire et écrire sur les sorties physiques, les fabricants n’ont pas cherchés compliqué : ils exécutent le CoDeSys Runtime en admin/root impliquant des potentiels upload de rootkits ;
- Aucun contrôle de Directory traversal n’est fait, ainsi il est possible d’écrire sur n’importe quel fichier.
Ces différents problèmes induisent des possibilités d’accès pour des attaquants et des utilisations détournées des PLCs. A l’heure actuelle, une coupure sur une chaîne de production peut coûter très cher à l’heure, il est étonnant qu’aucune équipe d’assurance qualité n’ai décelé ces problèmes. Les deux auteurs ont pu, quant à eux, trouver environ 600 machines vulnérables directement accessible par internet :
- Un premier scan de toute la plage IPv4 avec UnicornScan pour trouver les machines ayant les bons ports ouverts (1200 ou 2455), ce scan a prit environ 6 mois ;
- Un second scan sur le sous-ensemble obtenu à l’aide d’un script NMAP pour identifier les machines ayant un CodeSys vulnérable puis ensuite contacter les CERT correspondant et collaborer avec les entités concernées.
Ils avaient au préalable pris soin de définir sur le serveur effectuant les scans une page de contact indiquant leur démarche et ce qu’il fallait faire pour être retiré de la liste des IPs a parcourir, ils ont également évités les blocks d’IP réservés. A noter qu’ils n’ont reçus que 11 demandes de retrait, laissant penser que personne ne s’est inquiété de ces scans et qu’un an après avoir contacter les administrateurs, la majorité des PLCs vulnérables sont toujours accessibles, effrayant.
Petite statistique intéressante, ils ont estimés le coût du scan à $0.86 par PLC, qui aurait pu descendre à $0.11 en utilisant ZMAP.

Après cette présentation très réussie, c’est la pause déjeuner, et le moins que l’on puisse dire c’est que les organisateurs de Grehack ont fait les choses comme il fallait : le buffet était varié et très bon, du vin, de la bière, tout pour satisfaire les hackers que nous sommes. 1h de pause pour manger et discuter avant de repartir pour la deuxième partie de la journée, qui fera l’objet d’un billet séparé.
Annexe : Lien vers les slides – Lien vers les papers